Training an LLM to Trade Stocks with Reinforcement Learning
A 0.5B parameter language model, with absolutely zero training, made money trading stocks. It beat a PPO agent that had been trained for 20,000 steps. That result changed the direction of this entire project.
This is the story of building a full-cycle RL system for stock trading — from designing the environment to fine-tuning DeepSeek-R1 7B with supervised learning and reinforcement learning. It started as a Meta PyTorch hackathon submission and turned into something much bigger.
The idea
Most LLM trading projects do one of two things: they either use an LLM to generate trading signals from news, or they slap a PPO agent onto price data and hope for the best. Neither approach uses the LLM as the actual decision-maker inside a proper RL loop.
I wanted to build the full thing. An RL environment that speaks natural language. An LLM that receives market observations as text, reasons about them, and outputs trading actions. Then train that LLM using reinforcement learning — specifically GRPO, the same algorithm DeepSeek used to train R1 — so the model discovers strategies on its own.
Designing the environment
The environment replays real OHLCV data from 68 stocks on the Indian NIFTY index, covering 5 years of daily prices (2020-2026). An agent starts with cash, receives market observations at each step, and submits actions: BUY, SELL, or HOLD with position sizes.
Three difficulty levels test different skills:
- Easy — single stock, 20 trading days. Can you read momentum?
- Medium — 10 stocks, 30 days. Can you manage a portfolio?
- Hard — 25 stocks, 40 days. Can you handle noise at scale?
Scoring is a weighted composite: 40% risk-adjusted returns (Sharpe ratio), 30% raw P&L, 15% drawdown control, 15% trading activity. This means you can't just get lucky on one big trade — you need consistency.
One decision shaped everything that followed: the environment produces observations in two modes. Text mode gives the LLM rich, human-readable market descriptions with labeled indicators — "RSI is 28.4 (oversold), MACD histogram is negative but narrowing." Numeric mode gives PPO a flat vector of the same values, minus the labels.
This is an intentional information gap. The text mode carries semantic meaning that a language model can reason about. The numeric mode is just numbers. I wanted to measure whether that gap matters. It does.
The system stacks like this:
- LLM Agent (DeepSeek-R1 7B) — zero-shot, then SFT, then GRPO
- Gymnasium Wrapper — direct Python calls, text/numeric observation modes, temporal splits
- RL Environment (v1.1.0) — market simulator, feature engine (7 technical indicators), portfolio tracker, grading system (3 task levels, weighted composite scoring)
- Real Market Data — 68 NIFTY stocks, 5 years of daily OHLCV (2020-2026)
Each layer only talks to the one below it. The agent sees text, the wrapper translates actions, the environment simulates markets, and MLflow tracks everything.
Why the environment is the hardest part
In supervised learning, the dataset is static. In RL, the environment IS the dataset. Change the reward function and every previous experiment becomes incomparable. Introduce a bug in the market simulator and your agent learns nonsense without telling you.
I versioned the environment like a software release. Semantic versioning for both the environment and individual tasks. Every API response carries env_version and task_version. Every experiment logged to MLflow records exactly which version it ran against. When I changed the grading formula, I could re-evaluate all agents on the new version with one command.
143 tests at 90% coverage. CI runs lint, tests, and a coverage gate on every push. This is not overkill for RL — it's the minimum.
Data splits are temporal, not random. Train on 2020-2023, validate on 2023-2024, test on 2024-2026. Random splits would leak future information into training, which is especially dangerous with financial data where regime changes matter.
The baselines
Before touching an LLM, I needed floors and ceilings. What does "good" look like? What does "doing nothing" score?
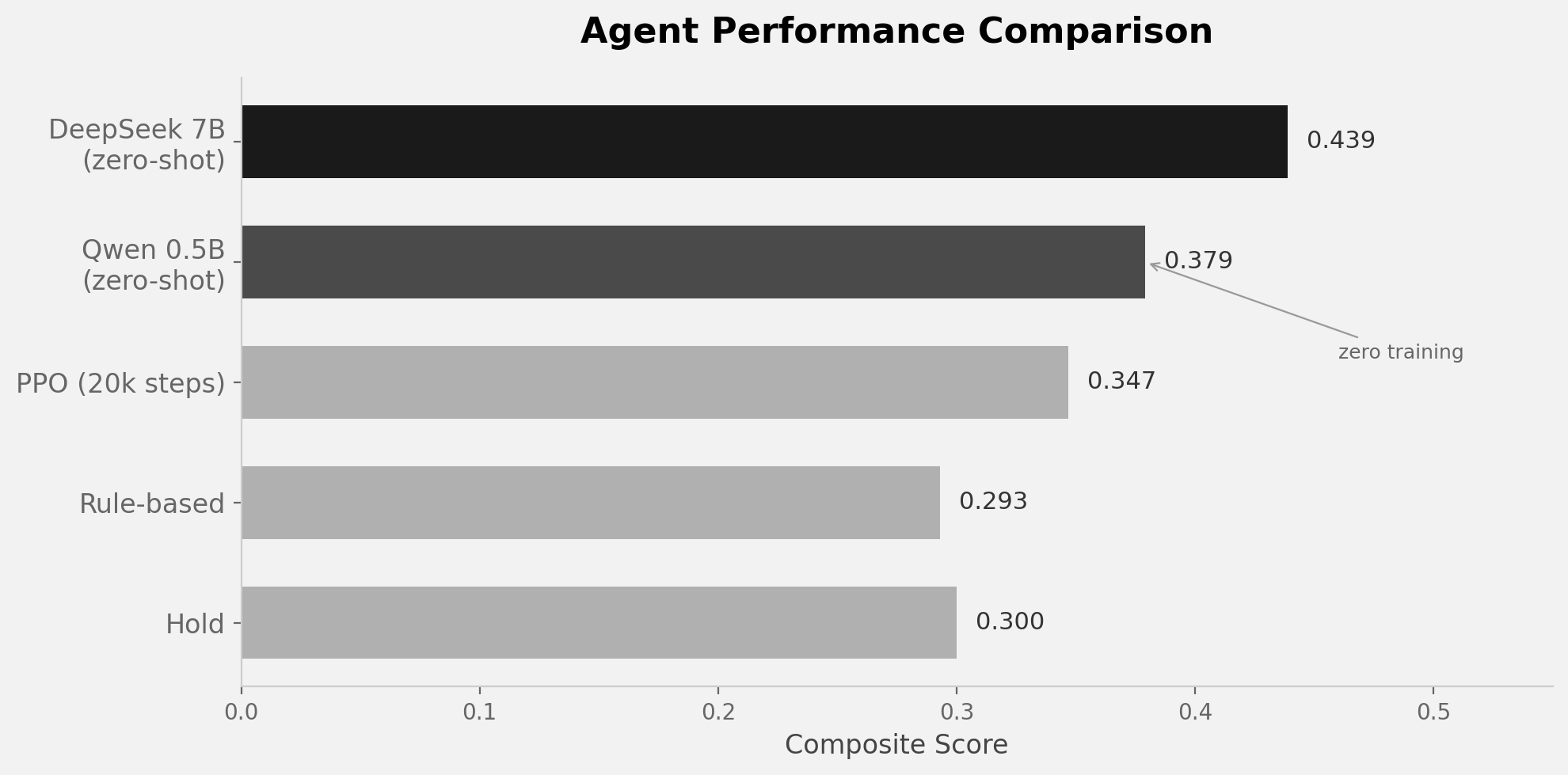
| Agent | Score | Return | Sharpe | What happened |
|---|---|---|---|---|
| Hold (do nothing) | 0.300 | 0.00% | 0.00 | The floor. Did literally nothing. |
| Rule-based (RSI rules) | 0.293 | -0.35% | -0.39 | Classic technical analysis. Lost money. |
| PPO (20k steps, numeric) | 0.347 | -1.30% | -0.29 | Trained for hours. Traded actively. Lost more. |
| Qwen 0.5B (zero-shot) | 0.379 | +0.53% | +0.18 | Zero training. Made money. |
| DeepSeek 7B (zero-shot) | 0.439 | -0.63% | -0.19 | Best score. Aggressive but unprofitable. |
The rule-based agent can't beat doing nothing. RSI/MACD rules that look reasonable on paper just don't work on this data. PPO trades more actively but loses even more — it sees only numbers and can't interpret market context.
Then the LLMs showed up.
The LLM surprise
Qwen 0.5B Instruct — half a billion parameters, no training, no fine-tuning — scored 0.379 and returned +0.53%. It made money. A model roughly the size of a large embedding model outperformed a PPO agent that trained for 20,000 steps.
The reason is the information gap. The text observation says "RSI is 28.4 (oversold), trend has been bearish for 5 days but momentum is shifting." PPO sees [28.4, -0.003, 0.72, ...]. The LLM reads the word "oversold" and knows what it means from pretraining. PPO has to learn that from scratch.
Scaling up to DeepSeek-R1 7B (distilled from the 671B R1) pushed the score to 0.439 — the highest so far. But interestingly, the 7B model lost money. It trades more aggressively, engages with the market more, but doesn't know when to sit out. It thinks extensively in its reasoning trace before every action, sometimes writing paragraphs of analysis, but still over-trades.
This pointed to exactly what training should fix: not teaching the model HOW to trade (it already knows the concepts) but WHEN to trade. Discipline, not knowledge.
Teaching discipline with SFT
The first training stage is supervised fine-tuning on expert trajectories. I ran the rule-based agent through the environment and collected 7,000 training examples — 4,000 from single-stock tasks and 3,000 from portfolio tasks.
Each example is a chat conversation:
System: "You are an expert stock trader..."
User: [market observation with RSI, MACD, Bollinger bands, etc.]
Assistant: "<think>RSI is 28, oversold territory. Trend has been
bearish but momentum is shifting. Risk is contained with stop-loss
at 2%. This is a high-conviction entry.</think>
BUY RELIANCE 0.5"
The <think> blocks are synthetically generated from the rule-based agent's decision logic. This matters for two reasons. First, it teaches the model to reason before acting — chain-of-thought for trading. Second, the reasoning traces become the substrate that GRPO will later optimize. The model needs to be able to articulate why it's making a decision before RL can improve those decisions.
Training runs on Kaggle's free T4 GPUs using Unsloth + QLoRA (4-bit quantization, LoRA rank 64). The 7B model fits in 5.4 GB of VRAM. Loss drops from 1.55 to 1.42 in the first 20 steps — the model is learning the format and trading patterns.
What's next: GRPO
SFT teaches the model to imitate. GRPO teaches it to improve.
The plan: generate multiple action sequences per market state, score each against the environment's reward function, and update the policy toward higher-scoring sequences. No critic model needed — GRPO uses group-relative advantages, comparing actions within a batch rather than against a learned baseline.
This is the same algorithm DeepSeek used to train R1. The hypothesis is that the model will discover strategies beyond what the rule-based expert taught it — better timing, smarter position sizing, regime awareness that the simple RSI rules couldn't capture.
The full loop will be: zero-shot baseline, then SFT for format and basic discipline, then GRPO for strategy discovery. Each stage has a clear purpose, and the evaluation harness makes it easy to compare results across all of them.
What this project is really about
This isn't about building a profitable trading bot. It's about building the complete RL pipeline for LLMs on a problem that's genuinely hard and measurable. The environment is versioned and tested, the experiments are tracked in MLflow, and every design decision — the information gap, the temporal splits, the synthetic reasoning traces — exists so that when the GRPO-trained model beats the zero-shot baseline, I'll know exactly why. And if it doesn't, I'll know exactly where to look.